- | Academic & Student Programs Academic & Student Programs
- | Regulation Regulation
- | Data Visualizations Data Visualizations
- |
Comparing Regulations across US States
Regulatory economists often focus their research on regulations originating from the federal government. Even for analyses of US states, they frequently focus on broad indices that attempt to measure the regulatory climate across states or the varying impact of federal rules on different states. More recently, however, State RegData—a database built on the QuantGov platform—gives researchers and policymakers the ability to conduct industry-specific analysis of state-level regulatory restrictions.
Extending the logic of the RegData project to US states, State RegData converts regulatory text in state administrative codes into datasets containing statistics about those regulations, such as restriction counts, word counts, and industry relevance. State RegData adopts the RegData methodology of using text analysis to quantify words and phrases that typically signify legal prohibitions or obligations in regulatory text—specifically, shall, must, may not, prohibited, and required. The project also uses machine learning algorithms to assess the probability that restriction counts are relevant to specific industries. The RegData project’s approach is more fully explained here.
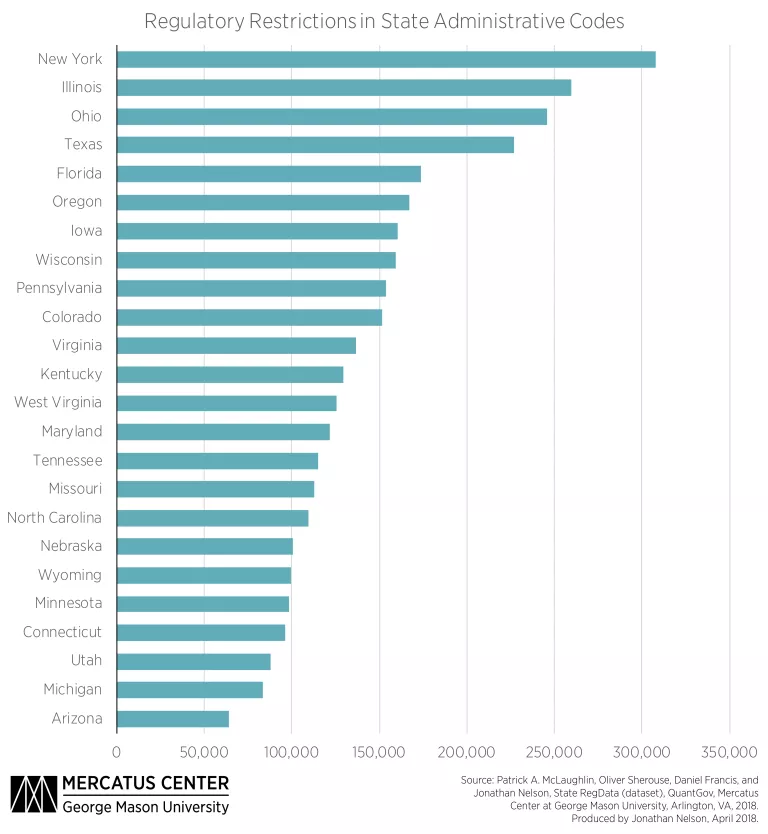
The quantification of regulatory restrictions permits comparisons across states. Since every dataset must be uniquely developed for each state administrative code, the scope of State RegData is still expanding, with 24 states currently represented as a cross section. So far, New York has the most regulatory restrictions in its administrative code, with more than 300,000 restrictions, while Arizona has the least, with fewer than 65,000 restrictions on the books. The majority of states fall between 100,000 and 200,000 restrictions. By comparison, there were about 1.08 million regulatory restrictions in federal regulations in effect at the end of 2017, which means that states on average appear to have roughly 10 to 20 percent the number of regulatory restrictions as the federal government.
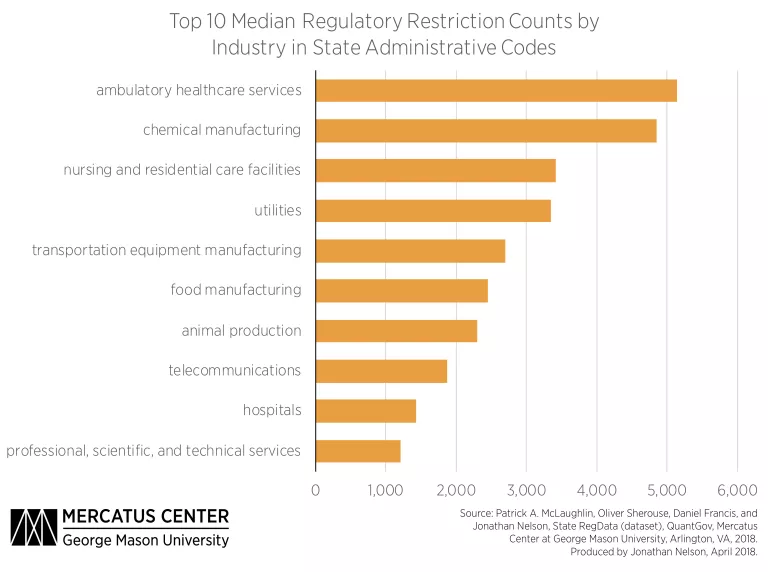
State RegData identifies industries by using the 2007 version of the North American Industry Classification System (NAICS) at the three-digit level. Unsurprisingly, the top 10 median industry-relevant restriction counts are concentrated in sectors such as medical services, manufacturing, and utilities. The most regulated sector is ambulatory healthcare services (NAICS code 621), with a median of about 5,000 restrictions.
State RegData will eventually cover as many of the states as possible. When State RegData is used in conjunction with data on federal regulations from RegData, researchers will have the opportunity to work with comprehensive data that use a consistent and comparable metric across time, place, and industry.
To speak with a scholar or learn more on this topic, visit our contact page.

