- | Regulation Regulation
- | Data Visualizations Data Visualizations
- |
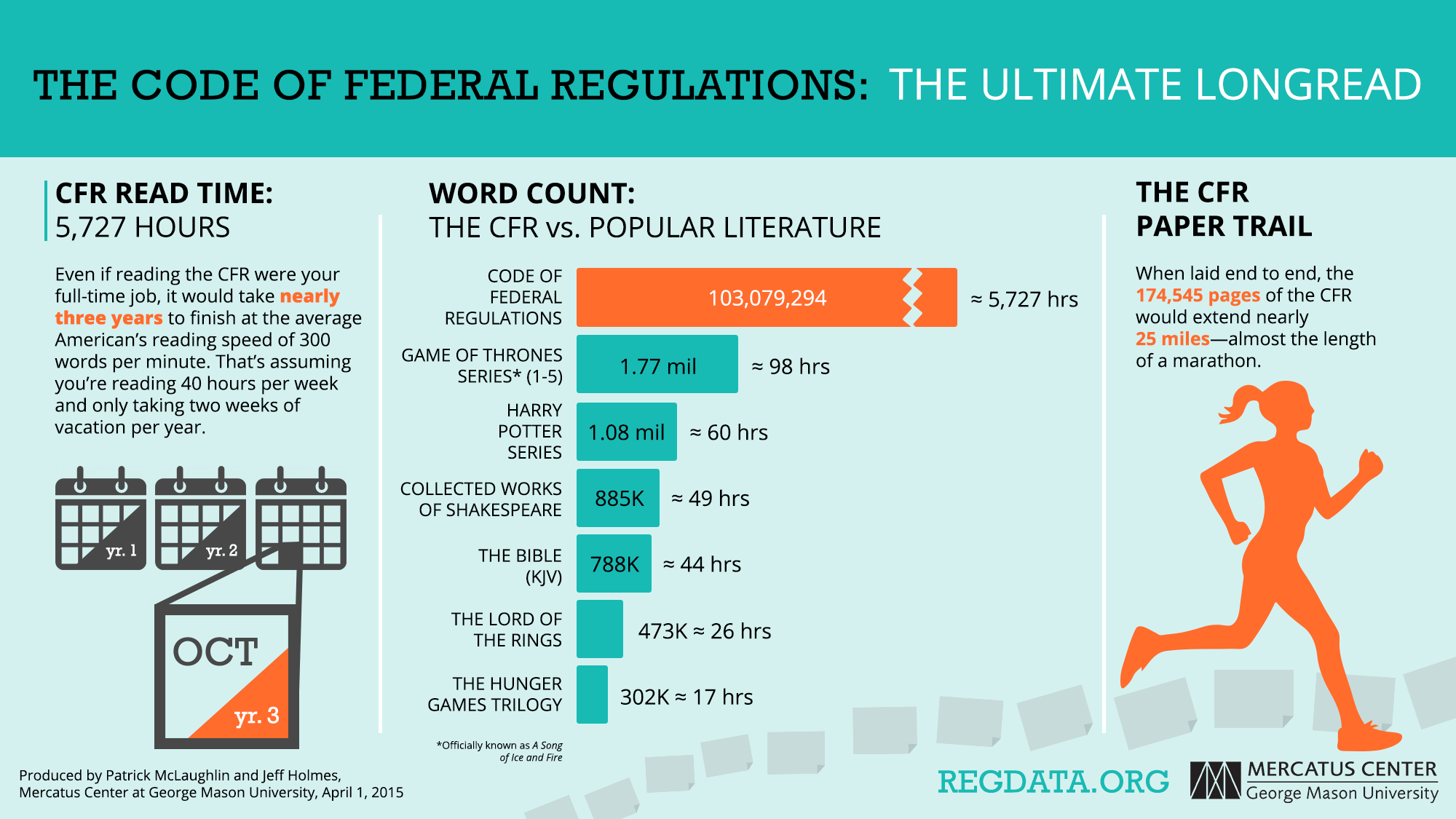
The Code of Federal Regulations: The Ultimate Longread
RegData was created to help us understand the size and scope of federal regulation and to enable researchers to learn more about the causes and consequences of regulatory accumulation. But why did we build computer programs to parse federal regulatory code, instead of reading it ourselves? Because it would have been impossible to read the entire Code of Federal Regulations and make any sense of it. Regulations have piled up and piled up to the point where no individual can make sense of them all.
The average adult reads prose text at a rate of 250 to 300 words per minute. If you read the Code of Federal Regulations at 300 words per minute on a full-time basis, it would take you nearly three years to get through just the version of the CFR published in 2012. That’s about 58 times longer than it would take to read through the five volumes currently published in George R. R. Martin’s fantasy saga, A Song of Ice and Fire. Or 220 times longer than it would take to read through The Lord of the Rings from the original R. R. of fantasy—J. R. R. Tolkien.
RegData’s programs, on the other hand, have not only read the 2012 CFR, but also the entire CFR published in each year from 1997 through 2012. This allows us to see how regulation has changed over time—which agencies have grown or shrunk, which industries are targeted more or less, and how major acts of Congress affect the rate of producing regulations. Before RegData’s creation, any attempts to answer these questions were simply . . . fantasy.
Related Content
- | Regulation Regulation
- | Data Visualizations Data Visualizations
The Accumulation of Regulatory Restrictions Across Presidential Administrations
- | Regulation Regulation
- | Data Visualizations Data Visualizations
The Dodd-Frank Wall Street Reform and Consumer Protection Act May Be the Biggest Law Ever
- | Regulation Regulation
- | Mercatus Original Video Mercatus Original Video
Visualizing the Growth of Federal Regulation Since 1950

- | Regulation Regulation
- | Expert Commentary Expert Commentary

