Algorithms
Algorithms are the software AI systems use to learn and make both decisions and inferences. The way they work, however, is often opaque and difficult to explain, which can lead to unintended consequences and low public trust. Policymakers need to understand the basics of AI algorithms and machine learning to develop policies that promote policy goals without stifling innovation.
Updated October 2024
“The only way to get artificial intelligence to work is to do the computation in a way similar to the human brain."
—Geoffrey Hinton, Nobel laureate and father of machine learning
This section of the AI Policy Guide covers AI algorithms and machine learning, including supervised, unsupervised, semi-supervised, and reinforcement learning. It also discusses the challenges of algorithmic bias and opacity and the advantages of neural networks.
Artificial intelligence (AI) algorithms serve two main functions: inference and learning. The goal of AI models is to produce statistical inference based on data—data for training the model and new data. For instance, a chess-playing AI system must infer the chess move that, from all available moves, is most likely to lead to victory. During learning, models improve their performance through iterative data analysis, which is known as training or, more narrowly, machine learning.
This section introduces algorithms. It discusses varieties of models, the way they learn, the way they perform inference, and the key challenges inherent in their application and design.
Key points:
Most AI algorithms are varieties of machine learning, a technique that produces intelligent systems through learning from input data or direct experience.
There are several variations and approaches to machine learning.
Neural networks are perhaps the most common technique used in designing AI models, including current cutting-edge applications.
As with the choice of data, the choice of algorithmic technology can both influence and bias results.
Many AI systems are opaque, and the process that leads to their predictions and decisions is often difficult to explain. AI explainability efforts are under way to render these processes transparent and understandable.
To promote AI quality and safety, many propose AI audits that would assess the biases, accuracies, and strengths of systems before and while they are deployed.
Algorithm Basics
This section addresses the basics of AI algorithms, machine learning, and associated policy.
Varieties of Machine Learning
Machine learning is a method for iteratively refining the process a model uses to form inferences by feeding it additional stored or real-time data. As a model takes in more data, the inferences should become more accurate: this is learning. Once inferences reach performance goals, the system can be put to practical use, inferring from new data. Notably, models are not necessarily fixed post-training; learning can continue after an AI model is put to practical use.
This section focuses on the dominant algorithmic technique for developing AI models—machine learning. Beyond machine learning, other methods are used to create AI models, including symbolic methods. Today, machine learning is the basis for most, if not all, modern systems. This technique is so dominant, in fact, that the term is largely synonymous with AI (box 6.1).
To create an AI system, engineers must select a machine learning algorithm. The algorithmic choice must be tailored to the task at hand. Although there is no one-size-fits-all strategy, most algorithms fall into one of the following categories:
Supervised learning. This approach follows a guess-and-check methodology. Data are fed into the model; the model forms a trial prediction (a guess) about those data and, critically, that result is checked against engineer-provided labels, an answer key of sorts. If the model’s prediction differs from the correct label, the model then tweaks its processes to improve inference. Successive iterations thus improve performance over time. This method is useful for well-defined objectives and for situations requiring human terms and understanding. For example, supervised learning can teach algorithms to label images of fruit with their correct English name. It has also found use in content and model behavior regulation. GPT-4’s engineers used supervised learning to fine-tune away certain undesirable behaviors and outputs. Although useful for helping models understand data from a human perspective, this method’s challenge is that models cannot learn what they are not trained to do. Their abilities are driven, restricted, and biased by the data chosen during the training process.
Unsupervised learning. Unsupervised learning algorithms are used when desired outcomes are unclear or broad. Unlike supervised learning, in which a system is trained to perform discrete and human-defined tasks, unsupervised learning models take in unlabeled data, sift through them, learn what hidden patterns and features they contain, and then cluster this information according to found categories and patterns. This approach is useful in data analysis, where humans are prone to miss important data features and overlook unobvious correlations. Likewise, large language models such as GPT-3 often use unsupervised techniques to develop their broad set of skills and pattern recognition abilities. Unsupervised learning benefits include looking at data through a detailed lens, doing so without many human biases and blind spots, and analyzing data with greater speed. Operating without a human-provided lens, however, can be a challenge. Although an unsupervised algorithm can categorize data and find patterns, it might not understand how to define its discoveries in human terms or match them to human objectives. Nonetheless, unsupervised techniques are behind many of the most cutting-edge systems in use today.
3. Semi-supervised learning. Semi-supervised learning is a hybrid of supervised and unsupervised learning that combines a portion of labeled data on top of a larger amount of unlabeled data. This approach provides a light touch of supervision that can be helpful when some guidance is needed to direct the algorithm toward useful conclusions. It can be useful, for instance, when categorizing written text. The unsupervised half might first cluster the symbols based on their shapes. Then to label these groupings, the AI can learn their names using a human-provided answer key. The result is an AI model that can recognize the alphabet.
4. Reinforcement learning. Reinforcement learning is driven by process rather than by data analysis. These algorithms use trial and error rather than big data to figure out the process behind a given task. To learn, an AI agent is placed in an environment and tasked with either maximizing some value or achieving some goal. A driverless car might be tasked with minimizing travel distance between two points or maximizing fuel efficiency. The algorithm then learns through repetition and a reward signal. Through repeated trials, it tries a process and receives a reward signal if that process furthered its goal. It then adjusts its code accordingly to improve future trials. This gamified approach is useful when a general goal is known, such as maximizing distance traveled, but the precise means of achieving that goal are unknown. Reinforcement learning from human feedback, for instance, is a prominent technique for aligning models with human preferences by testing them on users and rewarding it when users rate results positively. Here the goal of “usefulness for humans” is known, but how to get there and what that means is fuzzy—reinforcement learning’s flexible style leans into that ambiguity. A major challenge with reinforcement learning is that sometimes AI can cheat by following strategies misaligned with human goals. For example, if the goal were to maximize fuel efficiency when navigating a group of naval vessels to a location, perhaps an AI might choose to destroy the slowest ships to increase total naval speed. Here the AI technically finds a more efficient process yet diverges from human intention.
In summary, supervised learning produces models that yield mappings between data, unsupervised learning produces models that yield classes and patterns in data, and reinforcement learning produces models that yield actions to take on the basis of data.
Learning and Inference
The following are high-level illustrations of how machine learning and model inference work. Later each of these is presented in a more detailed, yet still understandable, manner.
Learning. At a high level, how do AI systems learn? To illustrate this process, examine how a supervised learning algorithm builds its intelligence. Fundamentally, this process starts with two elements: data and the model one wants to train. To kick off the process, the as-yet unintelligent model will take in one piece of data from the dataset. Although it has not yet been refined in any way at this point, the model will then attempt an initial prediction based on that data. It does so to assess how well it performs so that improvements can be made.
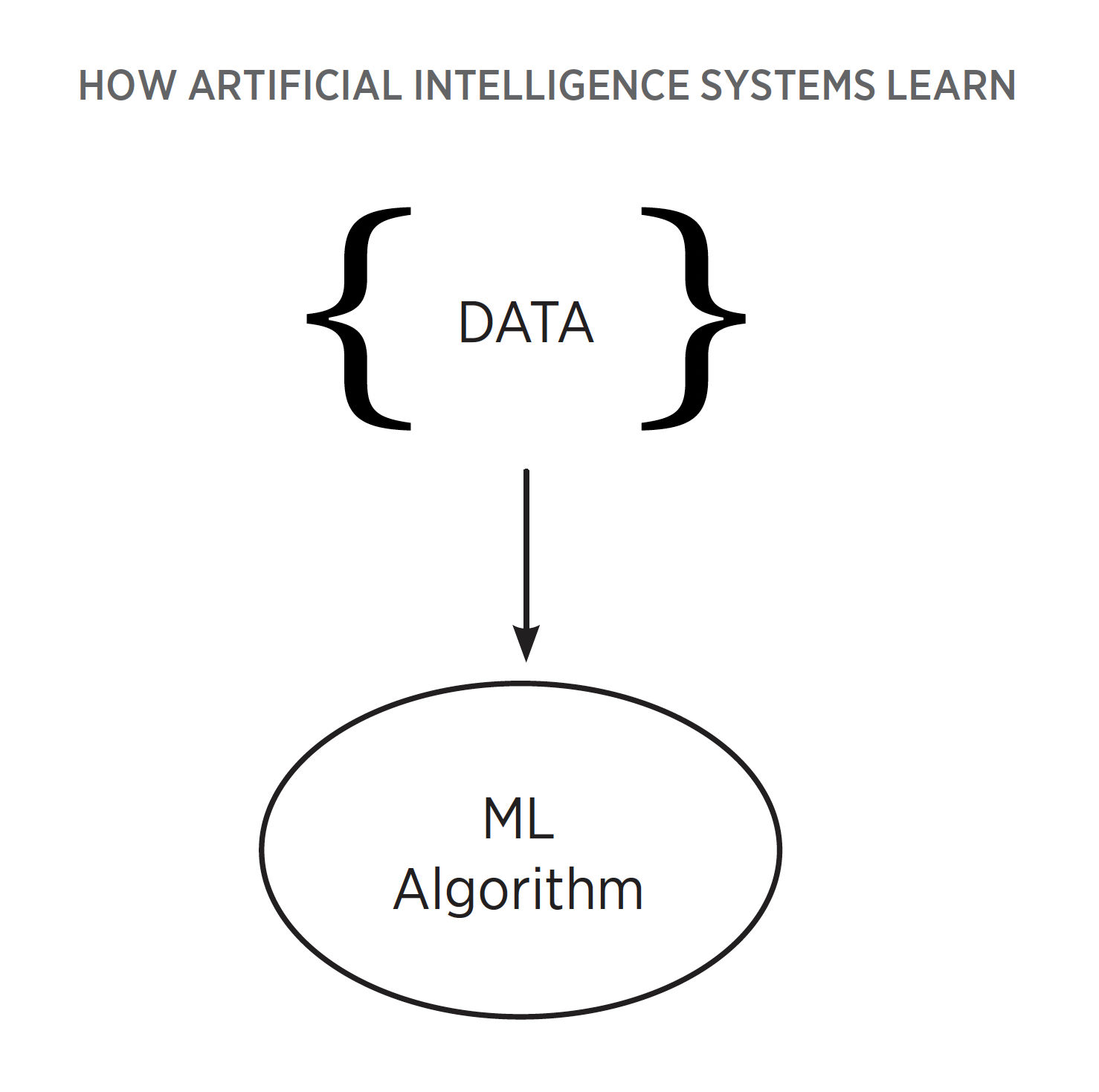
Once this initial prediction is made, the model then needs a benchmark to score how well it performed. There are many types of benchmarks, but in the case of supervised learning, one can use an answer key of sorts. Specifically, each data point will be given a human-provided label that represents the intended correct result. Suppose that the model is an image recognition system. If the training data included an image of an apple, it would be labeled with the correct term: “apple.” If the model incorrectly produced the prediction “pear,” the label would signal to the model that a mistake was made.
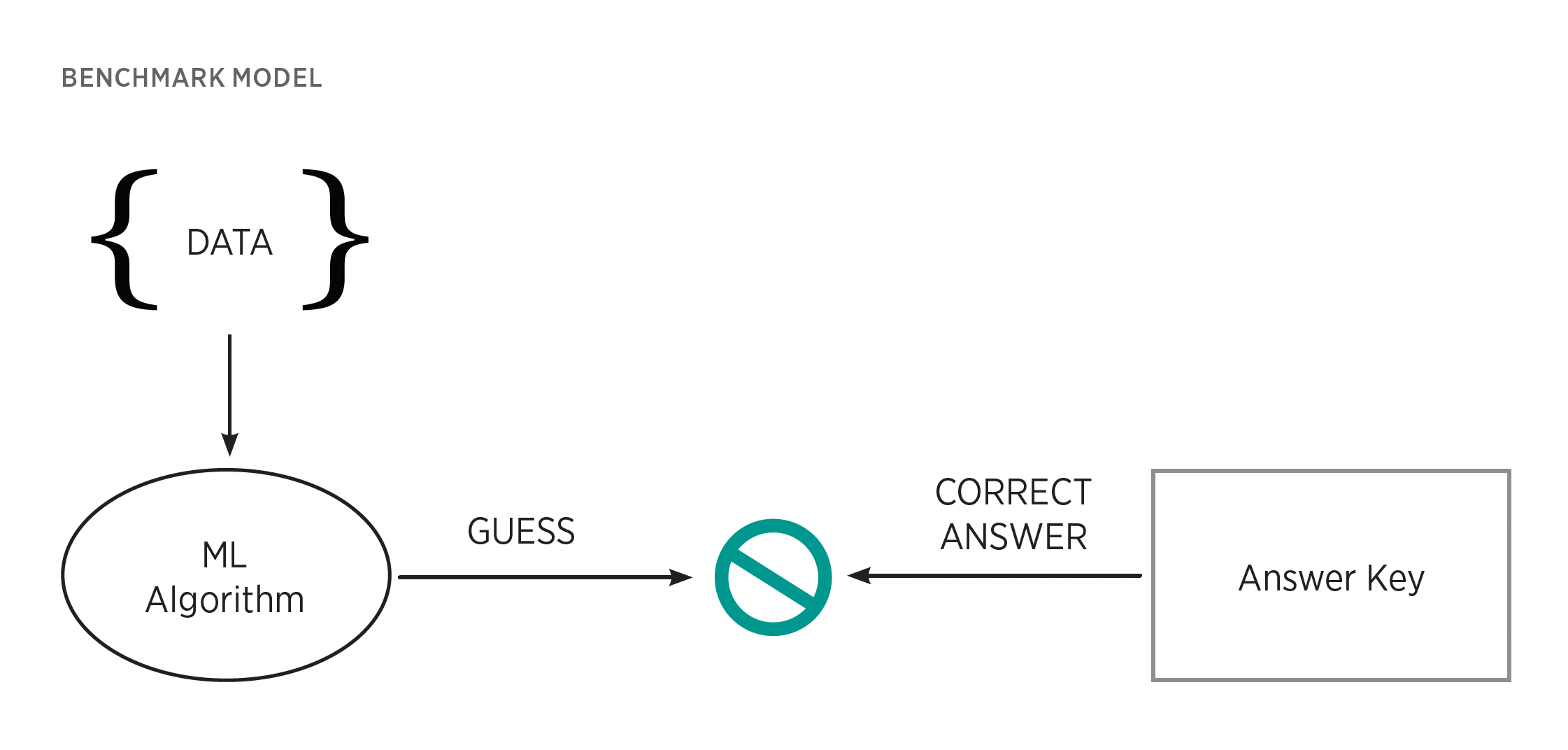
When the label and prediction differ, this incongruity signals to the model that it must change. Guided by a mathematic process, the model then gently tweaks certain internal settings and knobs called parameters, which are the values that shape its analytical processes. These tweaks ought to improve the model’s predictive abilities for future trials. Note that although guided by mathematics, these tweaks do not guarantee improvement.
The algorithm repeats this process on the next piece of data. With each iteration, the model tweaks its parameters with the hope that collectively, these small changes allow it to converge on a state where it can consistently and accurately make high-quality predictions. Recall that proper training can require millions of data points and, by extension, countless rounds of training to converge on somewhat-reliable inferences.
Once the machine learning process is complete, the fully trained model can then be deployed and perform inference on real-world data that it has not seen before.
Inference. Once training is complete, how do these models perform inference on never-before-seen data? As is often the case, there are many tools that can be used. As an illustration, however, examine the most popular: the artificial neural network (ANN). This work uses neural networks to illustrate AI inference because such networks are behind most modern AI innovations, including driverless cars, image generation, AI-powered drug discovery, and large language models. Just as machine learning has become synonymous with AI, many observers often treat neural networks as synonymous with machine learning. Unlike the difference between machine learning and AI, however, other approaches are still widely used and very popular. Examples include regression models, which act to map the relationship between data variables; decision trees, which seek to establish branching patterns of logic that input data can follow to reach a conclusion; and clustering algorithms, which seek to sort data into clusters based on various metrics of data similarity.
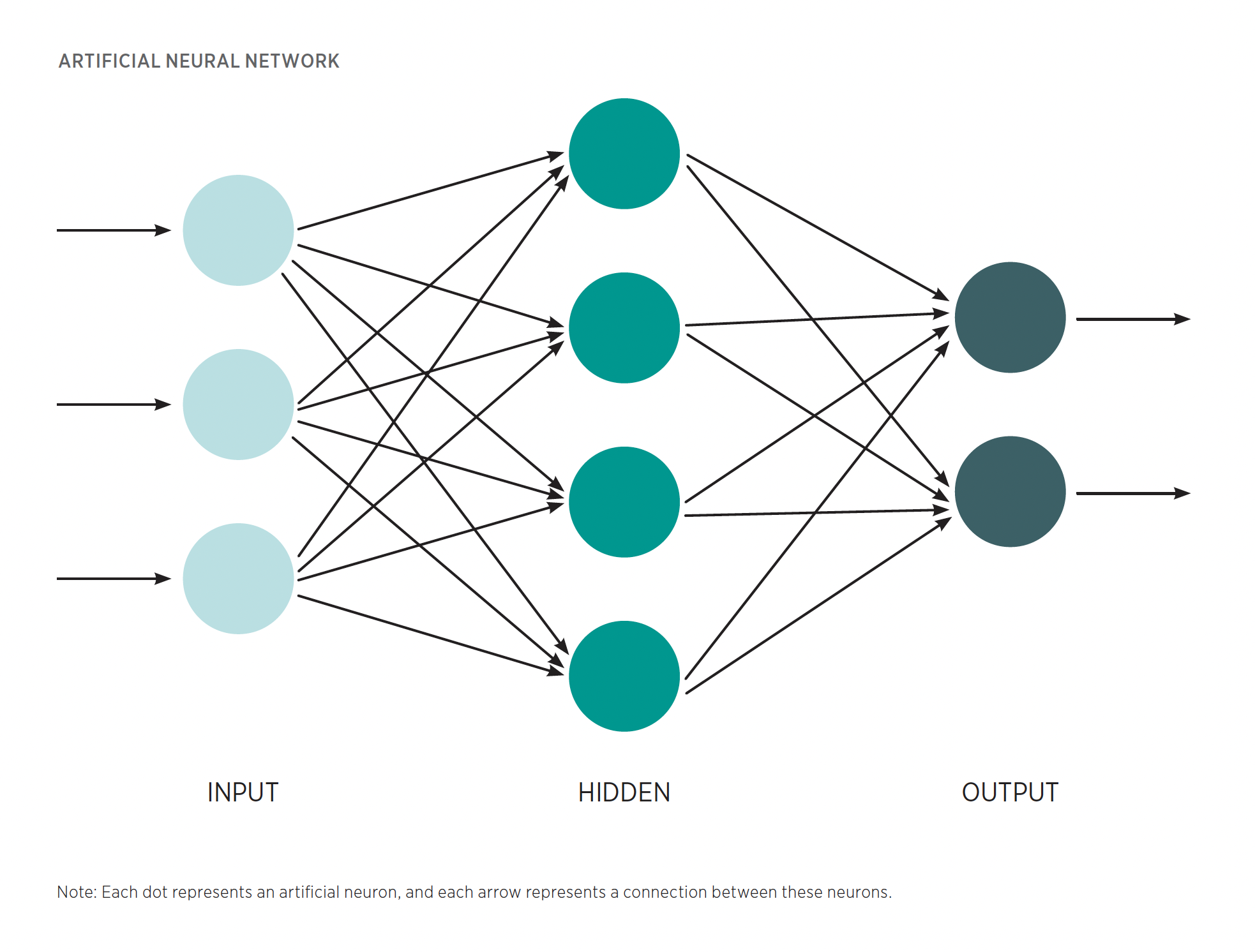
As the name implies, a neural network is an attempt to simulate the cognitive processes of the brain in digital form. These networks are composed of smaller units (the circles in in the above image) called artificial neurons. During the training process, each neuron will be tuned to find a unique and highly specific pattern in the input data that is highly correlative with accurate predictions. For instance, a neuron in a network designed to identify a face might be tuned to look for the visual patterns that represent a mouth, a pattern well correlated with faces. These patterns are the basis of the network’s decisions.
To analyze a given piece of data, the network will first pass that data point into a set of neurons called the input layer. This is the far-left column in the above image. Each neuron in this set will then examine the data for whichever patterns it has learned are significant. After this first round of analysis, these discovered patterns are then fired to downstream neurons.
When one neuron communicates with another, the information it sends is given a weight, which tells its neighboring neurons the importance of the pattern it has discovered for determining the final prediction of the network. Weighting certain patterns gives them an outsized influence on the final predictions. This approach is useful because it allows the network to prioritize what information is worth attention. If a network were trying to determine whether an image were a face, a freckle might receive a low weight because this feature is not highly indicative of a face; the freckle could be on an arm, a leg, or anywhere else. An eye, however, would receive an exceedingly high weight because this feature almost perfectly correlates with the prediction that an image is a face. These weights are one of the tunable parameters mentioned previously that are used to guide network analysis. Subsequent neurons take these weighted patterns and use them to find more complex patterns within patterns, developing an ever more nuanced picture of what the data represent. If two neurons have each identified an eye, these two features can be combined by a downstream neuron into the more complex and perhaps descriptive feature, “pair of eyes.”
At the end of this process, all of the information will be passed to the output layer of neurons that is tasked with determining which prediction is best correlated with the total sum of discovered patterns. That prediction will be the final output that can be used for further decisions, actions, or analyses.
Before moving on, note the advantages of this structure. First, this format allows the system to divide and conquer. With hundreds, thousands, and sometimes millions of neurons deployed to look for specific, fine-grained patterns, networks can capture the deep nuance and complexity of real-world data. Dividing and conquering gives networks both flexibility and greater accuracy.
Second, the connections between neurons allow for discoveries to be shared and combined, deepening analysis. Individual patterns, on their own, are often not enough to properly predict what data represent. By combining patterns through neuron-to-neuron communication, a neural network forms a more complete picture. To facilitate this, modern networks are often structured in layers of neurons, each of which takes in past patterns and recombines them in new and ever more complex ways. As a result, machine learning that uses neural networks is often referred to as deep learning, a term that describes the multiple layers of neurons that data must pass through before a final prediction can be made.
Generative AI
The recent explosion of AI interest largely centers on generative AI, systems trained to create high-quality text, media, or other data. Most generative AI systems today wield a shared model architecture, a deep learning design scheme that dictates how data interact with and flow through a model, called the transformer. What distinguishes the transformer is its ability to remember and connect disparate pieces of input data, rapidly process many data in parallel, and efficiently scale to learn and process a vast collection of data. The transformer has enabled the generative AI boom. This success, however, also rests on improvements in microchip processing power, specifically graphics processing units equipped to manage a transformer’s often immense scale, and the big data needed to capture the diversity of knowledge that generative systems require. The transformer’s flexibility has enabled immense breadth, finding application in image and video generators, voice cloning, music generation, machine translation, materials discovery, drug discovery, and other systems.
Large language models (LLMs)—generative models trained to understand, generate, and process human language—have received unique attention. LLMs include chatbots such as ChatGPT and Claude and machine translations systems. LLMs are also commonly integrated into other AI systems such as image and audio generation that require human language prompts. Likewise, language models are increasingly trending toward multimodality, or a model’s ability to understand or produce multiple types of data, often including text, image, video, audio, and various computer file types.
A key LLM and generative AI concern is hallucinations, outputs that are incorrect, unrelated to the prompt, or inconsistent with reality. While work is under way to decrease hallucinations, a perfect solution that always guarantees correct results is unlikely.
Key Challenges
The key challenges of algorithms are model bias, explainability, and auditing of AI.
Model Bias
As mentioned earlier, AI systems are not free from human biases. Although data are usually the root of many biased outcomes, model design is an often overlooked contributing factor. The frame of the problem that engineers are trying to solve with AI, for instance, naturally shapes how the model is coded.
For example, trying to design an AI system to predict creditworthiness naturally involves a decision on what creditworthiness means and what goal this decision will further. The model’s code will reflect this choice. If a firm simply wants to categorize data, perhaps a supervised learning algorithm can be used to categorize individuals. If the firm seeks to maximize profit, perhaps a reinforcement learning algorithm could challenge the system to develop a process that maximizes returns. These differences in goals and model design decisions will naturally change outcomes and create qualitatively different AI systems. How a model is trained can also affect results. A model intended for multiple tasks has been found to show different outcomes when trained on each task separately rather than all at once. Other such variations in the design process can be expected to yield varying results.
Mitigating this form of bias can be challenging and, like data bias, lacks a silver-bullet solution. Best practices are still developing, but suggestions tend to focus on process, emphasizing team diversity, stakeholder engagement, and interdisciplinary design teams.
Explainability
Deep learning promotes large algorithms with opaque decision processes. Generally, as AI models balloon in size and complexity, explaining their decision-making processes grows difficult. Decisions that cannot be easily explained are called black box AI. Large neural networks, and their convoluted decision paths, tend to fall into this category. As a result, interest has grown in explainable (or white box) AI, a field that involves either designing inherently interpretable machine learning models whose decisions can be explained or building tools that can explain AI systems.
Some classes of inherently interpretable models exist today. For instance, decision trees—models that autonomously create “if–then” decision trees to categorize data—can be visually mapped for users.
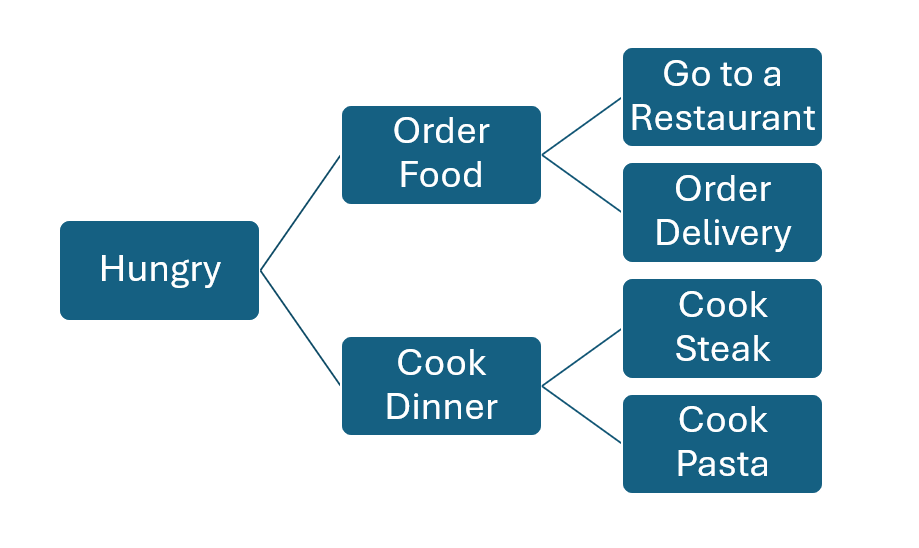
Inherently interpretable models, however, are limited in accuracy and scale. Few modern neural networks are inherently interpretable, and model interpretation tools form an area of active research and development. Examples include tools that can determine what features in the input data were most significant in determining the model’s conclusions. The field is deeply underdeveloped, however, and cannot provide model-wide explanations, explain correlations between features, or produce necessarily understandable explanations.
In many cases, applications of AI may require explainability. To abide by the law, an AI hiring system may need to prove that its decisions are not based on protected class characteristics. Explainability can also help maximize policy effect. If decision makers know how a system produces decisions or results, that knowledge can enable targeted modifications of code to improve functionality or perhaps minimize unwanted biases.
Auditing of AI
Tangential to explainability is AI auditing. Given concerns over fairness, bias, correct design, and accuracy, there is significant interest in evaluating AI systems to ensure that they meet certain goals. Proposing AI audits, however, is easier said than done. Implementation naturally requires clarity of purpose. AI design challenges are rooted not only in technology but also in data, the application of technology, and social forces imprinted in these systems via biases. Choosing which problems to solve and what benchmarks to hit is an inherently messy task. As discussed earlier in this work, evaluation metrics and benchmarks are diverse and application specific.
At present, technical and ethical standards are fragmented, with little broad-based consensus. A 2021 Arizona State University study found an unwieldy 634 separate AI programs dedicated to developing soft law—that is, nongovernmental standards for AI development and governance. This finding demonstrates that consensus has not been reached on the exact benchmarks and principles that might be used to audit AI.
Process is another challenge. As a relatively new concept, AI audits lack frameworks and best practices, and commentators have noted that research on testing, evaluation, verification, and validation of AI algorithms has not kept pace with other subdomains of AI innovation. Current processes and technologies offer no single audit technique that can test for the full range of possible errors.
Existing audits use a variety of methods. The data used to train algorithms can be audited to ensure that they are representative and avoid biases that might lead to disparate effect, or to simply eliminate data extraneous to engineering goals. Black box testing, in which test data are fed into systems to analyze behavior, can help analyze general accuracy and stress test for certain undesirable biases. Model code can also be analyzed to better understand its process and its decision-making. This method, however, is challenging because code is often complex and unwieldy, and the results of that code inherently depend on the inputs that are used.
As with all software, AI will be in a constant state of flux as updates are made and security patches released. Further, not all problems can be discovered through a single audit. Some challenges can be seen only once an AI is deployed in a complex human environment. To these ends, the National Institute of Standards and Technology (NIST) has proposed an iterative audit process that audits AI throughout its life cycle, during development and testing, and continuously after deployment. Repeated scrutiny could help catch errors at each stage of the process and reinforce design principles to ensure that they are always top of mind. NIST’s proposed process, however, is still in development. Best practices will require time and iteration before broad process agreement can be reached.
Each application naturally carries application-specific performance expectations. The issues faced by a medical AI system will differ from those of a music-generation AI. Determining the questions that must be asked, the processes followed, and the issues to be tested will therefore require diverse thought and subject-matter expertise. As with the field, AI audits depend on application.
Algorithms in Detail
The previous section discussed machine learning and AI inference at a high level. This section discusses how an individual neuron might take in data and spot patterns within those data to produce good predictions. The general principles are illustrated by use of the common supervised learning process and the Perceptron, a simple yet powerful artificial neuron model.

This is a diagram of an artificial neuron. On the left, the blue circles represent the input data for analysis. On the far right, the black arrow represents the final prediction that the model will output for the user. The core magic of this model, however, is the center. There one finds several elements that, while perhaps complex-looking at first, are relatively simple in operation.
An example follows.
Input
Start at the far left with the blue data inputs. For this example, suppose one operates a bank and is trying to train an algorithm to categorize loan applicants as either prime or subprime borrowers. Now suppose the applicants must submit four categories of data:
Whether they hold a savings account: represented by a 1 (yes), or a 0 (no)
Their number of dependents
Their number of monthly bank deposits
Their income bracket (represented by 1–7, with 7 being the highest)
For this illustration, suppose that the loan application for the neuron to analyze is as follows:
Savings account: 1
Number of dependents: 0
Number of monthly deposits: 2
Income bracket: 7
Data Adjustment and Activation
Detecting patterns in data is actually a process of transforming input data into an output that represents a meaningful pattern. This is done in two steps. First, the neuron manipulates the input data to amplify the most important information and sums the data. Next, it passes this sum to an activation function. In a realistic sense, the activation function represents the rules that transform the input data into the output decision. In many cases, however, it can more or less be thought of as an algorithmic trigger that needs to be tripped for the neuron to activate. The activation function compares the manipulated data to certain criteria, which dictate the final output that the neuron will produce. In the simple prime or subprime case, this criterion is a threshold number: if the sum is higher than this threshold, the neuron sends a result indicating that this is a prime borrower. If not, it indicates subprime. Although in this case, the result is the neuron’s final decision, note that in complex neural networks, the result might just be one of many patterns identified in service of the final decision.
Elements of an Artificial Neuron
Next, examine the tools that this neuron uses to adjust the data and calculate the final result. Surprisingly, this can be quite simple. In many cases, the math involved uses only simple arithmetic.
Once the data enter the neuron, they encounter the green squares in above diagram showing a model of a perceptron; each of these squares represents a weight. Using weights, the neuron can amplify a certain element of the input data through multiplication. For instance, it is likely that the income bracket data in this example are strongly correlated with prime borrowers; therefore, this feature of the data should be amplified in the final decision. To do so, one multiplies that value by a weight to make it bigger, giving it more significance.
Weights are a useful tool because they allow the truly important elements of the data to have an outsized effect on the result. Crucially, weights are a parameter that can also be tuned. The more important the value, the bigger a weight multiplier it will receive. Conversely, unimportant data can be eliminated by multiplying them by 0. Finding the correct weightings of data values can be seen as one of the core elements of a neuron’s intelligence.
After the data have been weighted, they are added to a bias value. The bias acts as the threshold, mentioned previously, that the weighted data must surpass for the neuron to activate. Put another way, the bias puts a thumb on the scale of the result by adjusting what causes the neuron to trigger. For instance, if prime borrowers should be rare, one might subtract a bias value, making it harder for the summed weighted data to trip the activation function.
After the data have been adjusted, they are then fed to the activation function. In the example neuron’s case, if the final value adds up to 1 or greater, the neuron communicates a prime result; if not, it indicates subprime.
Calculation of the Result
Let’s assemble each element to see how it affects the data. As mentioned earlier, to produce a result the neuron will simply take the input data—the loan application—multiply each category by its weight, and add these results with the bias value.
In this case, start by weighting the data. The data values are in blue, their weights in green, the bias in purple, and their sum in red:

Each data category is multiplied by a weight consistent with the importance of that data element in making final predictions. Run the data through this equation:
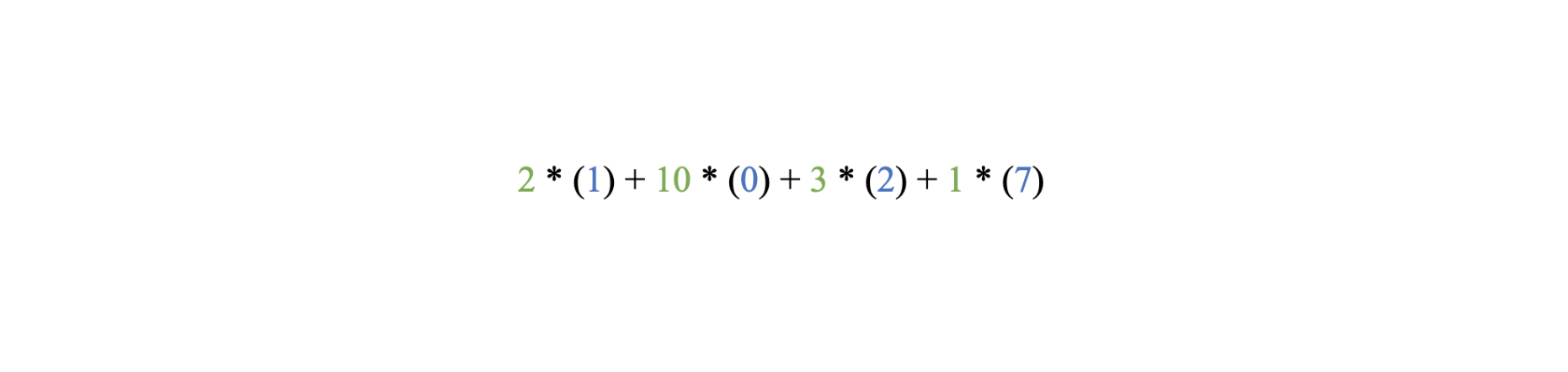
The weighted data sum is 15.
Next, add the bias. Remember that the bias is essentially the threshold that the data need to surpass for the neuron to activate. According to the rules prescribed by the activation function, these values must be greater than or equal to 1 for the neuron to indicate a prime value. The result is in red, the weighted sum from the previous step is in black, and the bias is in purple:
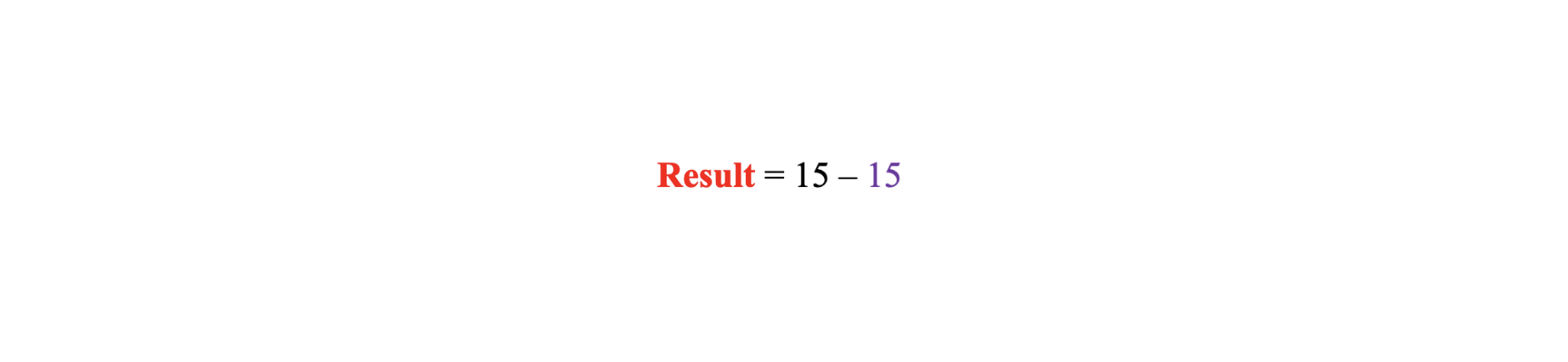
The result is 0. Therefore, the neuron chooses to categorize the data as subprime.
The Learning Process
For the sake of illustration, suppose that the model is currently in training and this result is not correct. The original data show that the individual is in the highest tax bracket and likely a prime borrower, yet the model in its current form classified the person as subprime. Thankfully, machine learning algorithms can learn from their mistakes and revise their weights and biases to produce better predictive outcomes.
How might this work? First, the algorithm must realize there was a mistake. In supervised learning, to train a model, engineers will use a dedicated set of training data paired with labels that act as an answer key. In this case, the model will compare its result to the key and find that it made a mistake. This result will prompt the algorithm to adjust its parameters.
These changes are often made using educated guesses, guided by mathematics. There are a variety of methods, but usually the algorithm will base its actions on how much its prediction diverged from the correct answer. This is called the loss. That value is then used to adjust each of the weights up or down depending on whether they are causing the neuron to undershoot or overshoot the correct result. The goal is to minimize this loss value in future iterations.
For the sake of simplicity and sanity, the somewhat complicated linear algebra involved here is not discussed. The key takeaway is that to improve, the algorithm adjusts its weights based on how much it erred, nudging the model in the direction of the correct answer. Each adjustment is not perfect, but a mere educated guess. After enough trials, however, the process helps minimize loss and optimizes the algorithm.
Back to the example, suppose the model has subsequently altered its weights to make better predictions:

Using this equation, the data would produce a result of 63. This is obviously greater than 15, the threshold that the results must surpass for the activation function to signal a prime result. The model has now learned when to classify this individual as a prime borrower.
Training Considerations
Once a network is properly trained, its results are tested using a dedicated set of test data. This test set includes unused data to assess accuracy and flexibility. Test data help avoid the problem of overfitting, a situation in which a model is tuned so precisely to the training data that it cannot adequately account for unexpected variations in new data. The opposite problem is the challenge of underfitting, a situation in which the model has not been properly tuned to the problem because of poor data or design, and accuracy suffers. Both can be detected using test data. When designing models, engineers must strike a balance between overfitting and underfitting.
Model Tuning
Recent research suggests that adding greater depth and more neurons does not diminish returns on predictive performance. That said, simply building increasingly massive models is not always feasible, given limitations in computing power. Model designers must therefore size their models to fit the data and computational power at their disposal. For instance, a programmer with just a simple laptop CPU wouldn’t be able to design a model with hundreds of thousands of neurons. Insufficient data also constrain model size. The bigger the model, the more data it will need to be well tuned. If engineers do not have enough data, they would choose model alternatives that are smaller and differently resourced.
Beyond the size and scope of models, engineers also work to tune a model’s hyperparameters, the settings that control the model’s function. An example of a hyperparameter is the learning rate. This rate dictates how large the tweaks to the model’s weights will be each time it makes an adjustment. A higher learning rate increases training speed, at the cost of accuracy, and a lower training rate decreases training speed, with accuracy gains. The chosen settings, as with model size, depend on the engineer’s specific resources and goals.
Finally, the engineer must also choose the correct model. Not all models are equal, and each comes with different strengths. Engineers must choose the best model for their goals. If a model for a given task does not exist, engineers can of course develop their own. That said, the majority of machine learning engineering relies on prefab models found in numerous libraries, many of which are free and open source. For example, the scikit-learn library includes a multitude of models that can be freely used and implemented using the Python programming language.
Note that most AI engineering is unscientific. Rules of thumb have come to dominate AI. There are no set rules that govern the specific number of neurons required, for instance. This adds further bias to AI. These algorithms, much like data, are reflections of the skill and goals of engineers. The systems are not perfect nor are they scientific. They can, however, still produce highly accurate results.
Model Variety
The neuron illustration specifically presented a feed-forward neural network, a classic form that takes in data and directly maps them to a specific output. For the prime/subprime categorization task, this process worked perfectly. However, not all tasks are quite so straightforward. Some data, such as text, depend on complex relationships. The placement of a given word in a sentence depends not only on the words before it but also on those that follow. Analyzing a sentence requires a network that can analyze each word sequentially and keep track of how each word fits into the context of the sentence. Even more complexity enters the picture when neural networks are applied to generative tasks—that is, when they are asked to produce text, paint pictures, write songs, and so forth. These complex tasks are not simple categorization exercises. As such, numerous tools and models have been developed to augment the basic neural network structure and account for the unique complexities that come with each type of task.
The following is a short list of some of the dominant forms of neural networks and the tools used by these networks to produce high-quality results. Given the dynamism of the field, this list cannot detail all types and combinations of neural networks nor can it predict which may fall out of favor.
Diffusion models. These models learn to generate new data, such as images, by gradually removing noise from a random input. Imagine starting with a blank canvas and randomly splattering paint all over it. The diffusion model learns to slowly and carefully remove the random splatters, step by step, until a clear, recognizable image emerges. It does this by training on a large dataset and learning the patterns and structures present in the data. The model can then apply this learned knowledge to generate new, previously unseen data similar to the training data. As of 2024, diffusion models have shown state-of-the-art results in generating highly realistic images, video, and audio.
Generative adversarial neural networks (GANs). A GAN is a training model that uses two separate neural networks that compete against each other to learn and improve. One produces fake data trying to trick the other into misclassifying them as real, while the other is competing to improve its abilities at distinguishing the fake data from the real data. This process creates an arms race of sorts, with both models adjusting themselves to improve their ability to produce fake data that look real and their ability to distinguish real from fake, respectively. Theoretically, both models improve, and this refinement results in the ability to produce high-quality artificial data. This method is widely useful in applications in which unique data must be generated, including AI-created art, images, video, and deep fakes.
Convolutional neural networks (CNNs). CNNs are neural networks used in image and video analysis. These models uniquely use convolutional layers, which act as data filters trained to spot and separate patterns that are highly correlated with a specific result. The result from these layers simplifies data and accentuates the most important features. For example, if an algorithm is trained to recognize dogs in images, a convolutional layer may be trained to specifically find the pixel data patterns that form floppy ears. If this layer spots this pattern, there is a high likelihood that the image is indeed a dog. Overall, these layers act to break down images into their component patterns and unlock greater predictive powers for neural nets.
Recurrent neural networks (RNNs). These networks are defined by their ability to “remember.” As data flow through an RNN, they are analyzed on their own merits, and their qualities are knit together and compared to the data that came before, allowing the network to see patterns over time. This temporal analysis quality has applications in time-dependent data such as video or writing.
Transformers. An architecture that arrived in 2017, it has since been widely applied across many complex tasks such as natural language processing. Transformers’ key selling point is their attention mechanism, which allows the model to “pay attention” to key features and remember how those features in the data relate to others. This quality allows these models to treat data as a complex whole, a characteristic that is essential for any task that requires understanding over time, such as reading text. Because the transformer is an architecture, it is often used in concert with other models. OpenAI’s Sora video generator, for instance, is a diffusion transformer using both diffusion models and the transformer architecture. The basis for many foundation models today is the transformer.
